Die NFDI4Memory Incubator Funds
Innovative Ideen gefördert bekommen
Die „NFDI4Memory Incubator Funds“ werden jährlich ausgeschrieben und dienen der Förderung innovativer und experimenteller Projektideen. Ziel ist es, die bestehende Innovationskraft unseres Arbeitsprogramms strategisch zu erweitern und an die Bedarfe unserer Community anzupassen.
Die Projektideen sollen dabei verschiedene, mit den Aufgaben von NFDI4Memory in Zusammenhang stehende Ziele verfolgen, etwa die Vertiefung des Arbeitsprogramms in den Task Areas, die Erprobung innovativer Methoden und Projektideen oder die konkrete (Weiter-)Entwicklung von Tools oder Services. Die einzelnen Projektideen können so immer einer oder mehreren entsprechenden Task Areas zugeordnet werden, mit der oder denen in enger Abstimmung zusammengearbeitet wird.
Die Ausschreibungen richten sich an Forschende aus historisch arbeitenden Geisteswissenschaften sowie an Bibliotheken, Archive, Museen und Gedenkstätten. Die antragstellenden Einrichtungen sollen entweder bereits Participant von NFDI4Memory sein oder können durch die Incubator Funds-Förderung Teil des Konsortiums werden.
Die Laufzeit der geförderten Projekte beträgt in der Regel mehrere Monate. Die verschiedenen, bisher geförderten Einzelprojekte konnten eine Fördersumme von bis zu 65.000 € beantragen. Jedoch können sich auch kleinere Projekte um eine Förderung bewerben, da eine Wirkung in die Breite beabsichtigt wird.
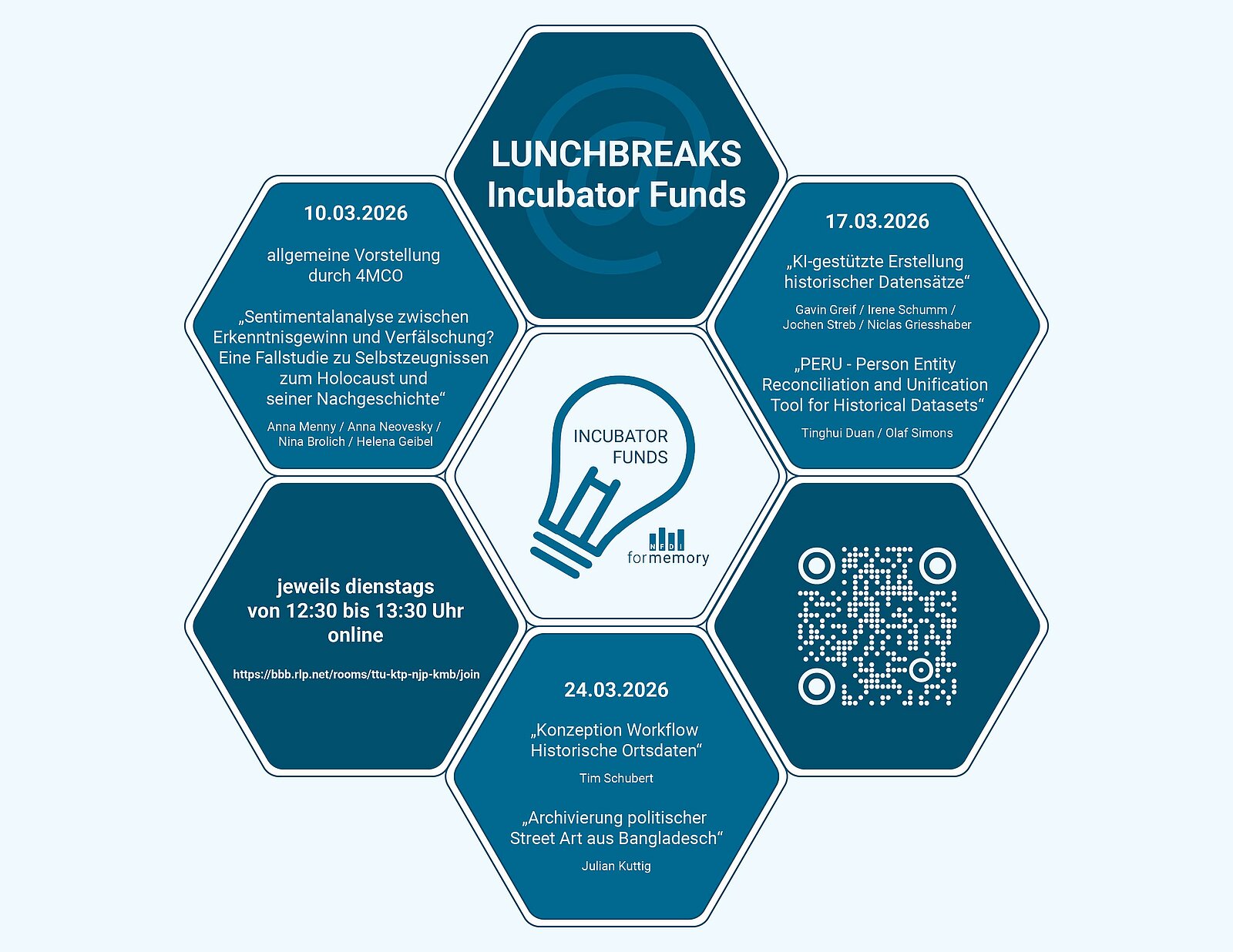
Lunchbreaks@Incubator Funds 2026
In den Lunch Breaks@Incubator Funds stellen sich die diesjährig geförderten NFDI4Memory Incubator Funds Projekte vor.
Die Incubator Funds werden seit 2024 jährlich ausgeschrieben und dienen der Förderung innovativer und experimenteller Projektideen.
Die Teilnahme an den Lunch Breaks bedarf keiner Anmeldung, die Veranstaltung ist frei über BigBlueButton zugänglich.
Link zum BBB-Raum
FAQ zu den Incubator Funds
- Die Incubator Funds Projekte für 2027 werden im Sommer 2026 ausgeschrieben. Die Ausschreibung wird auf dieser Webseite veröffentlicht, folgen Sie auch unserem Newsletter, um die Veröffentlichung nicht zu verpassen.
Die 4Memory-Incubator Funds richten sich an Forschende aus historisch arbeitenden Geisteswissenschaften sowie an Bibliotheken, Archive, Museen und Gedenkstätten. Wir fördern Antragstellende auf jedem Karrierelevel.
Die antragstellenden Einrichtungen sollen entweder bereits Participant des 4Memory-Konsortiums sein oder können durch die Incubator Funds-Förderung Teil von 4Memory werden, sofern sie die Fördervoraussetzungen der DFG erfüllen.
Die Ausschreibung wird von der Task Area „Participation and Steering“ organisiert. Die Anträge werden vom Steering Committee des NFDI4Memory-Konsortiums nach den in der Ausschreibung genannten Kriterien bewertet (Double Peer Review).
Nach der Entscheidungssitzung des Auswahlgremiums im Herbst 2026 melden wir die zur Förderung vorgeschlagenen Einrichtungen, die noch keine Participants in 4Memory sind, zwecks Prüfung ihrer Förderfähigkeit an die DFG. Anschließend werden die Fördermittel im Rahmen eines Mittelweiterleitungsvertrags bereitgestellt, dessen Abschluss grundlegende Voraussetzung für die Weiterleitung von Fördermitteln ist. Dieser Vertrag wird mit der Einrichtung geschlossen, an der das IF-Projekt angesiedelt ist.
Grundsätzlich kann sich eine Einrichtung, die bereits über ein anderes Incubator Funds-Projekt gefördert wird oder wurde, nochmals bewerben. Eine Verlängerung des bereits geförderten Projekts ist allerdings nicht förderfähig, weil jedes IF-Projekt zu einem konkreten Ergebnis kommen soll.
Ein (weiterer) Förderantrag muss dezidiert eine neue Entwicklungsstufe der Arbeit (technische Weiterentwicklung, Vertiefung, Erweiterung usw.) beinhalten.
Wir empfehlen auch hier eine frühzeitige Kontaktaufnahme mit den TAs, in denen das Projekt sich verortet.
Neue Participants können nur im Rahmen der Incubator Funds in das Konsortium aufgenommen werden. Der Participant-Status bezieht sich dabei auf eine Einrichtung (z.B. eine Universität), nicht auf eine einzelne Person. Aktuell hat 4Memory knapp 70 Participants und ist auf diese Weise in der Lage, die vielen Perspektiven der historisch arbeitenden Community mit einzubeziehen.
Participants gehören einer oder mehreren Task Areas an, über die ihre Arbeitsergebnisse ins Konsortium und in die weitere Community fließen.
Participants leisten durch ihre Expertise, ihr Engagement und ihre Netzwerke einen wesentlichen und dauerhaften Beitrag zum Arbeitsprogramm von 4Memory. Im Rahmen der Incubator Funds bringen Sie sich als Participant über Ihr gefördertes Projekt aktiv in die inhaltliche Arbeit des Konsortiums ein. Den Umfang Ihres Engagement legen Sie in Ihrem Projektantrag fest.
Incubator Funds Projekte 2026
Projekttitel:
Archivierung politischer Street Art aus Bangladesch: Ein Good-Practice-Modell für transnationales FDM
Projektlaufzeit:
01.03.-31.12.2026
Projektverantwortliche & beteiligte Einrichtungen:
Dr. Julian Benedict Kuttig, Research Centre Global Dynamics der Universität Leipzig
Beteiligt: FID Südasien, Universitätsbibliothek der Ruprecht-Karls-Universität Heidelberg
Das ist unser Ziel:
Ziel des Projekts ist die systematische Dokumentation, wissenschaftliche Erschließung und nachhaltige Sicherung politisch motivierter Graffiti aus der „Juli-Revolution“ 2024 in Bangladesch. Die oft ephemeren Wandbilder werden als zeithistorisch relevante Quellen verstanden, die Protestdynamiken, gesellschaftliche Aushandlungen und Zukunftsentwürfe sichtbar machen. Aufbauend auf bestehenden Kooperationen soll ein langfristig verfügbarer digitaler Bestand entstehen, der zugleich ethisch reflektierte und partizipative Archivierungspraktiken etabliert und lokale Akteur:innen aktiv einbindet.
So wollen wir unser Ziel erreichen:
Die Umsetzung erfolgt in Kooperation mit dem „Heritage – Archives of Bangladesh History“ sowie durch die Integration in die Infrastruktur HeidICON an der U Heidelberg über eine Kooperation mit dem FID Südasien. Die Bilddaten werden nach LIDO -Standards erschlossen, mit kontrollierten Vokabularen versehen und mit DOIs veröffentlicht. Ergänzend werden rechtlich-ethische Fragen geprüft und ein Praxisleitfaden entwickelt.
Das hat unser Ziel mit 4Memory zu tun:
Das Projekt unterstützt zentrale Ziele von NFDI4Memory durch die nachhaltige Sicherung und Standardisierung zeithistorischer Quellen. Es stärkt Datenqualität, Interoperabilität und Nachnutzbarkeit gemäß FAIR- und CARE-Prinzipien. Mit seinem transnationalen, ethisch reflektierten Ansatz erweitert es die Digital Area Histories und entwickelt Strategien für verantwortungsvolles Forschungsdatenmanagement.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Die historisch arbeitenden Geistes- und Sozialwissenschaften erhalten Zugang zu bislang kaum erschlossenen Quellen politischer Alltagskultur aus Bangladesh. Die offene Bereitstellung über etablierte Infrastrukturen sowie die Anbindung an zentrale Repositorien erhöhen Sichtbarkeit und Nachnutzbarkeit. Forschende können die Daten für historische, politikwissenschaftliche oder kulturwissenschaftliche Fragestellungen weiterverwenden. Zugleich bietet der Praxisleitfaden übertragbare Workflows für den Umgang mit visuellem Material, multilingualer Erschließung und transnationaler Kooperation.
Weiterführende Links: https://heidicon.ub.uni-heidelberg.de/search & https://heritage-archives.org/
Projekttitel:
KI-gestützte Erstellung historischer Datensätze: Aufbau
einer universellen Benchmark- und Mikrodatenbank für die deutsche Geschichtsforschung
Projektlaufzeit:
01.03.-31.12.2026
Projektverantwortliche & beteiligte Einrichtungen:
Prof. Dr. Jochen Streb, Dr. Irene Schumm, Niclas Grießhaber, Gavin Greif, Lehrstuhl für Wirtschaftsgeschichte der Universität Mannheim, Forschungsdatenzentrum der Universitätsbibliothek Mannheim
Projekttitel:
Sentimentanalyse zwischen Erkenntnisgewinn und Verfälschung? Eine Fallstudie zu Selbstzeugnissen zum Holocaust und seiner Nachgeschichte
Projektlaufzeit:
01.03.-30.11.2026
Projektverantwortliche & beteiligte Einrichtungen:
Institut für die Geschichte der deutschen Juden (IGdJ): Dr. Anna Menny, Helena Geibel
Universität Erfurt (UE) & Fachhochschule Erfurt: Prof. Dr. Anna Neovesky, Nina Brolich
Das ist unser Ziel:
Unser Ziel ist es, durch die Anwendung bestehender Tools und Modelle für die Sentimentanalyse zu einer kritischen Reflexion maschineller Analyseverfahren und ihrer Einsatzszenarien im Hinblick auf die Auswertung und Deutung von Selbstzeugnissen zum Holocaust und seiner Nachgeschichte beizutragen. Mit der Übertragung der Sentimentanalyse auf historische Texte und der tiefergehenden Analyse von Emotionen werden neue methodische Zugänge für die historische Forschung erschlossen und evaluiert sowie didaktisch als Lerneinheit aufbereitet.
So wollen wir unser Ziel erreichen:
Das Trainingskorpus besteht aus mehreren Tagebüchern der Theresienstadt-Überlebenden Martha Glass, die mittels Sentiment- und Emotionsanalyse systematisch hinsichtlich emotionaler Ausdrucksformen untersucht werden. Die Analyse erfolgt entlang zweier methodischer Stränge: einem lexikonbasierten und einem Machine-Learning-Ansatz. Anschließend werden die Ergebnisse beider Verfahren ausgewertet und verglichen und daraus Empfehlungen abgeleitet.
Das hat unser Ziel mit 4Memory zu tun:
Mit der Erschließung neuer Bereiche und methodischer Zugänge für die historische Forschung hat das Projekt enge Bezüge zum übergeordneten Ziel von NFDI4Memory. Die Erstellung eines Trainingsdatensatzes ebenso wie die Entwicklung einer Typisierung bzw. Ontologie für emotionale Ausdrucksformen in historischen biografischen Quellen hat einen großen Bezug zur TA2. Die werkzeugkritische Betrachtung und Evaluation methodischer Ansätze sowie die Entwicklung einer Lerneinheit fügen sich in die Ziele der TA4.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Das Projekt…
- leistet einen Beitrag zur Reflexion der Nachnutzungspotentiale von Forschungsdaten und liefert damit Impulse für die Methoden des Forschungsdatenmanagements
- liefert Impulse für eine digitale Quellenkritik, indem Werkzeuge und Methoden ergebnisoffen und quellenkritisch getestet und evaluiert werden
- trägt dazu bei, Arbeitsweisen, Tools und Methoden durch das Erproben und Darstellen möglicher Nutzungsszenarien zu erproben und zu etablieren
- leistet einen Beitrag zum Einsatz von Forschungsdaten in der Lehre durch Formulierung von Lerneinheiten als OER und als Praxisprojekte für Studierende
- gibt Impulse für die fachübergreifende Vernetzung zum Einsatz computerlinguistischer Verfahren, ML und LLMs bei der Analyse historischer Quellen
Weiterführende Links:
Barbara Müller-Wesemann, Martha Glass. „Jeder Tag in Theresin ist ein Geschenk“, in: Hamburger Schlüsseldokumente zur deutsch-jüdischen Geschichte, 31.01.2021. <https://schluesseldokumente.net/beitrag/jgo:article-270> [09.01.2026].
Martha Glass: Theresienstädter Tagebücher 1943-1945, veröffentlicht in: Hamburger Schlüsseldokumente zur deutsch-jüdischen Geschichte, <https://schluesseldokumente.net/quelle/jgo:source-217> [09.01.2026].
Projekttitel:
PERU – Person Entity Reconciliation and Unification Tool for Historical Datasets
Projektlaufzeit:
01.03.-31.12.2026
Projektverantwortliche & beteiligte Einrichtungen:
Dr. Markus Meumann, Dr. Martin Mulsow, Forschungszentrum Gotha der Universität Erfurt
Das ist unser Ziel:
Entwicklung und Veröffentlichung des Web-Tools PERU zur automatisierten Reconciliation und Unification von Personen-Entitäten in historischen Datensätzen. Damit sollen Dubletten reduziert, Datenqualität und Interoperabilität verbessert und Pilotdatensätze (Erfurter Matrikel, Repertorium Germanicum) für den Import in Wikibase-Systeme wie FactGrid/Wikidata vorbereitet werden.
So wollen wir unser Ziel erreichen:
Umsetzung als Web-App in vier Phasen: Kernentwicklung, LLM-gestützte Übersetzung natürlichsprachlicher Regeln in Matching-Logik, Pilot 1 mit der Erfurter Matrikel, Pilot 2 mit dem Repertorium Germanicum sowie anschließend Workshop, Feedback-Runde, Open-Source-Release, Dokumentation und (Video-)Tutorials.
Das hat unser Ziel mit 4Memory zu tun:
Das Projekt adressiert zentrale 4Memory-Ziele in TA 2 Data Connectivity: Es stärkt Datenqualität und Interoperabilität durch automatisierte Entity Resolution, reduziert den Aufwand nachträglicher Dubletten-Zusammenführung, unterstützt FAIR-/CARE-orientierte Nachvollziehbarkeit und bindet historische Forschungsdaten besser in bestehende Wikibase-Infrastrukturen ein.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Die Community profitiert von einem offenen, nachnutzbaren Werkzeug, das als Open-Source-Software auf GitHub veröffentlicht wird. Historiker:innen und Citizen Scientists werden in der Entwicklungsphase eingebunden; ihr Feedback erweitert die Regelbasis. Geplant sind Präsentationen auf Fachveranstaltungen, ein Community-Workshop im November 2026 sowie detaillierte Dokumentation, Blogbeiträge, Videos und die langfristige Archivierung der bereinigten Daten auf Zenodo und in FactGrid.
Projekttitel:
Konzeption eines Workflows und zugehöriger Toolchains zur Erfassung, Verarbeitung, Zusammenführung und (Nach)Nutzung historischer Ortsdaten
Projektlaufzeit:
01.03.-31.12.2026
Projektverantwortliche & beteiligte Einrichtungen:
Prof. Dr. Joachim Schneider (Institut für Sächsische Geschichte und Volkskunde, Projektleitung)
Tim Schubert (Institut für Sächsische Geschichte und Volkskunde, Projektbearbeitung)
Das ist unser Ziel:
Unser zentrales Ziel ist es, einen konkreten Workflow und passende Toolchains für die optimale Erfassung, Verarbeitung und Nachnutzung von historischen Ortsdaten zu entwickeln. Damit wollen wir die bisher uneinheitliche Verwaltung dieser Daten ablösen, Fehlerquellen reduzieren und gleichzeitig die digitalen Kompetenzen von Forschenden im Umgang mit Normdaten nachhaltig stärken.
So wollen wir unser Ziel erreichen:
Wir setzen auf einen stark kollaborativen und iterativen Ansatz, der in vier Phasen abläuft:
1. Bedarfsanalyse: Ermittlung der Anforderungen durch eine breit angelegte Umfrage und bilaterale Dialoge,
2. Erstkonzept: Erstellung eines ersten Workflow-Vorschlags samt verschiedener Toolchains,
3. Feedbackrunde: Einholen von praxisnahem Feedback zum Konzeptentwurf, unter anderem über Workshops,
4. Finalisierung: Überarbeitung und Fertigstellung des Workflows basierend auf den Rückmeldungen der Community.
Das hat unser Ziel mit 4Memory zu tun:
Unser Vorhaben setzt das NFDI4Memory-Bestreben um, Akteur:innen zu vernetzen und Forschungsdaten nach den FAIR-Prinzipien standardisiert und interoperabel nutzbar zu machen. Die Ergebnisse des Projekts fließen direkt in die Struktur des Konsortiums ein: Der Workflow soll in das Beratungsangebot des NFDI4Memory-Helpdesks integriert werden und dient als Lehrmaterial für den Data Literacy Learning Hub sowie HistoCat. Zudem kann er als Vorlage für den Umgang mit anderen Normdatentypen innerhalb des Konsortiums dienen.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Die Community – von Forschenden über GLAM-Einrichtungen bis hin zu Citizen Scientists – ist eingeladen, sich aktiv über Umfragen, bilaterale Einzelgespräche und Feedback-Workshops an der Gestaltung des Workflows zu beteiligen.
Am Ende profitieren alle historisch arbeitenden Akteur:innen von den frei zugänglichen (Open Access), modular aufgebauten Leitlinien und Toolchains. Diese erleichtern nicht nur die eigene Arbeit, sondern ermöglichen auch einen effizienten und standardisierten Datenaustausch über Institutionsgrenzen hinweg. Die technische Dokumentation wird zudem transparent auf GitHub/Zenodo veröffentlicht.
Weiterführende Links: https://ortsdaten.hypotheses.org/
Incubator Funds Projekte 2025
Projekttitel:
4Memory@School - Lehr-Lern-Labor: Digital History Data
Projektlaufzeit:
März - Dezember 2025
Projektverantwortliche & Beteiligte Einrichtungen:
Prof. Dr. Sander Münster, FSU Jena, Juniorprofessur für Digital Humanities
Das ist unser Ziel:
Ziel des Projektes ist es, dass angehende Pädagoginnen eigene digitalgestützte Lehrangebote zu geschichtlichen Themen entwickeln, erproben und reflektieren und sich Schülerinnen auf digitalem Weg mehrperspektivisch mit Geschichte auseinandersetzen können. Damit verbunden wird die Digital- und Datenkompetenz von Studierenden und Schülerinnen gestärkt und der Einsatz von digitalen Arbeitstechniken zur Erforschung, Aufbereitung und Präsentation
geschichtlicher Themen evaluiert und befördert.
So wollen wir unser Ziel erreichen:
Im Labor werden Studierende verschiedener Fachrichtungen zu Tutorinnen ausgebildet. Sie entwickeln Kursangebote für Schülerinnen, die sie dann im Nachmittagsbereich einer Schule, als Ferienprojekt in einem Jugendzentrum oder in den Laborräumlichkeiten der Universität
durchführen.
Das hat unser Ziel mit 4Memory zu tun:
Mit 4Memory@School wird bereits frühzeitig Forschungsdatenkompetenz vermittelt und an
digitale Methoden in den historisch orientierten Geisteswissenschaften herangeführt.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Im Projekt werden im Rahmen von Lehrangeboten niederschwellige Workflows zur Erhebung, Analyse und Verwendung digitaler Forschungsdaten (3D, Fotos, Bild-Text-Beschreibungen) von stadtraumlichen Objekten entwickelt und erprobt. Die Community kann sich mit Themen und Ideen einbringen. Die entstehenden Lehrkonzepte und -materialien werden zur Weiternutzung zur
Verfügung gestellt. Mit der Einbindung von Schülerinnen und angehenden Lehrenden werden neue Communities erschlossen und zur breiten Nutzung und Awareness für die durch 4Memory adressierten Themenstellungen beigetragen.
Weiterführende Links:
https://www.gw.uni-jena.de/13480/forschung
Projekttitel:
Aufbau und Bereitstellung eines Benchmark-Datensatzes von historischen Tabellen
(1750-1990)
Projektlaufzeit:
01.03.2025 - 31.12.2025
Projektverantwortlicher:
Prof. Dr. Werner Scheltjens, Professur für Digitale Geschichtswissenschaften, Otto-Friedrich-Universität Bamberg.
Beteiligte Einrichtungen:
(1) Prof. Dr. Mark Spoerer, Lehrstuhl für Wirtschafts- und Sozialgeschichte, Universität Regensburg;
(2) Gesellschaft für Sozial- und Wirtschaftsgeschichte
Das ist unser Ziel:
Kernziel des Projekts ist die Entwicklung eines umfangreichen und reprasentativen Datensatzes historischer Tabellen aus der Zeit von 1750 bis 1990. Durch Annotation wird dieser Datensatz als Service für die Entwicklung von Kl-basierten Lösungen für das Problem der Text- und Datenerkennung in historischen Tabellen aufbereitet und verfügbar gemacht. Mit dem annotierten Datensatz wollen wir die Entwicklung innovativer KI-gestützter Lösungen für die Erkennung (Layout und OCR) historischer Tabellen beschleunigen, indem wir einen Wettbewerb planen. So vertiefen und fördern wir die Zusammenarbeit zwischen Computer Scientists und HistorikerInnen.
So wollen wir unser Ziel erreichen:
Um unser Ziel zu erreichen, werden wir eine Auswahl von ca. 10.000 gedruckten historischen Tabellenseiten aus dem Zeitraum von 1750 bis 1990 - von der frühstatistischen Zeit bis zu den Anfängen des WWW - bearbeiten. Die Auswahl soll die Vielfalt und die historische Entwicklung tabellarischer Datenrepräsentationen widerspiegeln und die Merkmale der Tabellen in Labels (Annotationen) erfassen. Wir streben eine Verteilung an, die der relativen Bedeutung der Jahrhunderte in unserem Untersuchungszeitraum entspricht (15% 1750- 1800; 30% 1800-1900 und 55% 1900-1990), und widmen uns ausschließlich ganzseitigen, doppelseitigen und mehrseitigen Tabellen. Das hat unser Ziel mit 4Memory zu tun: Unser Projekt trägt zu den LINKAGE-Zielen des 4Memory- Konsortiums bei. Das Projekt stellt einen standardisierten Datensatz bereit, der für die gesamte Community relevant ist, und trägt zur Suche nach Lösungen im Bereich der automatisierten digitalen Erschließung historischer Tabellenbestände bei. Das Projekt regt die Entwicklung von Kl- gestützten Lösungen an und verbindet dabei historische Quellenkritik und Data Services. Durch seine Ausrichtung trägt unser Projekt zur Vernetzung von Forschung, Dienstleistungen wissenschaftlicher Bibliotheken und Infrastruktur bei.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Der Benchmark- Datensatz kann als Trainingsdaten verwendet werden und eignet sich für die Ground-Truth- Produktion. Die historisch arbeitenden Geistes- und Sozialwissenschaften können somit direkt davon profitieren. Die Community ist herzlich eingeladen, sich mit Vorschlägen für die
Berücksichtigung einzelner Tabellen und Tabellenwerke an unserem Projekt zu beteiligen.
Projekttitel:
Transformation von Wissen aus domänenspezifischen Forschungsdatensammlungen in ontologiebasierte, frei verfügbare, normierte Vokabulare (Akronym: DomVoc)
Projektlaufzeit:
1.3.2025-31.12.2025
Projektverantwortliche & Beteiligte Einrichtungen:
Bärbel Kröger, Christian Popp, Niedersächsische Akademie der Wissenschaften zu Göttingen, Germania Sacra
Das ist unser Ziel:
Ziel des Projektes ist die Transformation von Wissen aus domänenspezifischen Forschungsdatensammlungen in ontologiebasierte, persistent adressierbare, normierte Vokabulare. Durch die Zentralisierung von Normdaten soll die bisher noch verbreitete, oft redundante lokale Haltung von Normdaten und Vokabularen aufgelöst werden. Der inhaltliche Schwerpunkt liegt dabei auf Entitäten zur religiösen Landschaft Europas im Mittelalter und in der Frühen Neuzeit.
So wollen wir unser Ziel erreichen: Im Rahmen des Projekts soll zum einen die Strategie für den Aufbau und die Bereitstellung von Normdaten in einer wikibase-basierten Instanz weiterentwickelt werden, die zum anderen exemplarisch an einem umfangreichen Datenkorpus in die Praxis umgesetzt wird. Hierzu wird der geschichtswissenschaftliche Wissensgraph FactGrid mit zentralen Entitäten zur europäischen Religionsgeschichte angereichert. Der Fokus liegt dabei auf der kirchlichen Führungselite des Heiligen Römischen Reiches und Spaniens (Bischöfe) und deren vielfältige Einbindung in kirchliche Institutionen (Bistümer, Stifte, Klöster, Kirchen etc.).
Das hat unser Ziel mit 4Memory zu tun:
Ein zentrales Anliegen der TA2 - Data Connectivity ist die Schaffung eines zentralen Normdatenregisters für historische Daten. Das hier beantragte Projekt zur Transformation von domänenspezifischen Forschungsdatensammlungen in ontologiebasierte, frei verfügbare Normdatenvokabulare mit Schwerpunkt auf die vormoderne Kirchengeschichte zielt daher auf einen Kernbereich der Projektziele von NFDI4Memory.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Abgesehen von der weitreichenden Vernetzung des Akademieprojekts Germania Sacra innerhalb des NFDI4Memory-Konsortiums und in der historischen Forschungslandschaft sichert die Nutzung der kollaborativen Plattform FactGrid die Einbindung der wissenschaftlichen Community. Bereits im Vorfeld der Antragstellung wurde gemeinsam mit einschlägigen Projekten der Mittelalterforschung an der Schaffung von normierten Daten gearbeitet
Weiterführende Links:
https://wiag-vocab.adw-goe.de, https://germania-sacra.de, https://factgrid.de
Projekttitel:
Embodied Interpretathon - Crowdbasierte Interpretation von mittelalterlichen
Bewegungsbeschreibungen
Projektlaufzeit:
01.06.2025 - 31.12.2025
Projektverantwortliche & Beteiligte Einrichtungen:
Dr. Eric Burkart, Germanisches Nationalmuseum Nürnberg (GNM)
Das ist unser Ziel:
Verknüpfung einer digitalisierten mittelalterlichen Handschrift aus den Beständen des GNM mit crowdbasiert erhobenen videografischen Daten, die in standardisierter Form konkurrierende moderne Interpretationen einer in der Handschrift detailliert beschriebenen Bewegung als Ergebnis einer von Citizen Scholars betriebenen Form von embodied research dokumentieren; Entwicklung eines Ansatzes im Bereich der Digital Public History zur Sammlung einer neuen Kategorie von Forschungsdaten (Video) aus dem Bereich des praktischen Wissens (Interpretathon); Publikation eines Video-Essays im Journal of Embodied Research zu performativen Methoden in der Geschichtswissenschaft und zum epistemologischen Status einer
modernen verkörperten Interpretation mittelalterlicher Aufzeichnungen
So wollen wir unser Ziel erreichen:
Auszüge aus der Handschrift GNM Hs 3227a zu einer Lektion der Kampfkunst von Johannes Liechtenauer werden transkribiert, in XML aufbereitet, textkritisch annotiert und in eine FUD-basierte kodikologische Datenbank zu mittelalterlichen Kampfbüchern eingepflegt. In einem über Social Media begleiteten Aufruf zur praktischen Interpretation werden Citizen Scholars aus der Historical European Martial Arts Community aufgefordert, im Zuge des durch Zoom-Tutorials und weitere Materialien begleiteten Interpretathons das in ihrer praktischen Beschäftigung mit mittelalterlicher Kampfkunst erworbene Bewegungswissen mittels Videografie standardisiert als Bewegungshypothese zu dokumentieren. Die Video-Daten werden aufbereitet, veröffentlicht und über eine Auszeichnung der XML-Transkription in der FUD-Datenbank mit der technischen Fachlexik der Handschrift verknüpft, um so als proof of concept den Grundstein für
die Erstellung eines videografischen Glossars zu legen.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Entwicklung eines innovativen Ansatzes im Bereich der Digital Public History; Erweiterung der bestehenden Kompetenzen und Methoden der 4memory Community im Bereich visueller Daten; Erweiterung der 4memory Community um GLAM Institutionen und Citizen Scholars als Beitrag zur Förderung
einer „Data Culture" in den historisch arbeitenden Disziplinen; Entwicklung eines an dem
bestehenden Verfahren eines Transcribathons orientierten prototypischen Konzepts fur einen
Interpretathon
Projekttitel:
VAMOD - Vormoderne Ambiguitäten modellieren. Anwendungsmöglichkeiten aus
dem östlichen Europa
Projektlaufzeit:
März-Dezember 2025
Projektverantwortliche & Beteiligte Einrichtungen:
Prof. Dr. Maren Röger, Direktorin, Leibniz-Institut für Geschichte und Kultur des östlichen Europa (GWZO) (Projektleitung)
Prof. Dr. Julia Herzberg, GWZO, Stellvertretende Direktorin, „Bibliothek und Digitales" (Projektverantwortliche)
Moritz Kurzweil, GWZO, Abteilung „Bibliothek und Digitales", Forschungsdaten-Manager
Dr. Sven Jaros, Martin-Luther-Universität Halle-Wittenberg / Aleksander-Brückner-Zentrum für Polenstudien, Datengeber, Historisches Institut der Polnischen Akademie der Wissenschaften
Kraków (IH PAN), Arbeitsstelle für das Historisch-Geographische Wörterbuch Kleinpolens
Dr. Waldemar Bukowski
Dr. Janusz Szyszka, FactGrid, Universität Erfurt, Forschungszentrum Gotha, Deutsche Nationalbibliothek (DNB Standort Leipzig)
Das ist unser Ziel:
Das Projekt verfolgt eine doppelte Zielstellung: Zum einen werden wir die Forschungsdaten der Dissertation von Sven Jaros (ca. 800 Urkunden mit ca. 1.600 Orts- und 5.000 Personendaten) nach den FAIR-Prinzipien über die OpenData-Graphdatenbank FactGrid verfügbar machen und mit Normdaten verknüpfen. Diese Daten werden anschließend persistent mit WikiData verknüpft. In vielfacher Hinsicht leisten wir damit Pionierarbeit, von der die historische Forschung nachhaltig profitieren wird: Für die Modellierung vormoderner Realitäten (politische Entitäten, Ämterlaufbahnen etc.) werden wir Guidelines erstellen, um die bislang häufig vernachlässigte geschichtswissenschaftliche Expertise ins Semantic Web zu bringen.
So wollen wir unser Ziel erreichen:
Das Projekt beginnt mit der Aufbereitung der Forschungsdaten, unterstützt durch einen OpenRefine-Workshop in Zusammenarbeit mit der DNB. Für die Lokalisierung und Identifizierung von Orten werden Datensatze des IH PAN genutzt. Auf Basis des Urkundenkorpus werden politische Entitäten und Herrschaftsstrukturen modelliert, einschließlich der Herrscherinnen Polens, Ungarns, Litauens und der Moldau. Die in den Urkunden erwähnten Personen spiegeln die adlige Elite Polen-Litauens im 14. und 15. Jahrhundert wider, d. h. es werden komplette Ämterhierarchien abgebildet. Auch beinhalten die Datensätze vielfältige Beispiele für adlige Mobilität und Migrationen sowie den Zusammenschluss zu Wappengeschlechtern. Im Ergebnis werden Typologien angelegt, etwa für Rechtsinhalte von Urkunden (Verleihung von Rechten/Besitzungen, Lokationen, Bestätigungen etc.) oder für Funktionen, die Personen in Urkunden ausfüllen können (Aussteller, Empfänger, Zeuge, Petent, Intervenient, Schreiber etc.). Diese Typologien und Best Practice Beispiele werden Open Access (etwa über zenodo) veröffentlicht und der historische Fachcommunity zugänglich gemacht. Zur Diskussion der Zwischenergebnisse ist ein Workshop mit dem Jenaer Projekt DigiHistDB geplant. Die persistente Verknüpfung von Datensätzen zwischen Wikidata und FactGrid garantiert eine hohe Sichtbarkeit sowie langfristige Zugänglichkeit der Projektergebnisse und verbessert gleichzeitig die Qualität öffentlich zugänglicher Forschungsdaten. In Zeiten von Desinformation leisten wir somit einen
wichtigen gesamtgesellschaftlichen Beitrag.
Das hat unser Ziel mit 4Memory zu tun:
VAMOD trägt auf verschiedene Weise zu den Kernzielen von NFDI4Memory und seinen Task Areas bei. Die Politik- und Herrschaftsgeschichte ist in den etzten zwei Jahrhunderten einen weiten Weg gegangen. Anstatt der starren Ausrichtung auf Nationalstaaten, Herrschaftsgebilde und Dynastien hat sie sich für die Ambivalenz und Unschärfen politischer Konfigurationen geöffnet. Politische Entitäten werden als Resultat von kontinuierlichen Aushandlungsprozessen verstanden. Nun stehen wir vor der Herausforderung, auch im digitalen Raum eine Ausdrucksweise zu finden, die diese komplexen, uneindeutigen Realitäten angemessen abbildet. VAMOD wird maßgeblich zum Gelingen dieses Reflexionsprozesses beitragen. Dieses ist umso wichtiger, um einem bereits erkennbaren „Data Bias" entgegenzuwirken. Bisher ist das östliche Europa in digitalen Wissensordnungen unterrepräsentiert. Somit werden wir die Diskussionen der Task Area Data Culture (Measure 1) maßgeblich befördern. Um sensible und angemessene Beschreibungen geht es zudem bei den Zielen, die eher die Task Area Data Quality berühren. Gerade Graph-Datenbanken wie FactGrid oder Wikidata stellen eine besondere Herausforderung für die Beschreibung komplexer historischer Realitäten dar. VAMOD wird hier durch die skizzierten Handreichungen (Measure 4) zur Modellierung vormoderner politischer Entitäten, Dynastien oder Eliten Pionierarbeit leisten. Den Standards bei FactGrid und Wikidata folgend, geht das Einpflegen der Datensätze auch mit der Verknüpfung mit Normdaten einher. An dieser Stelle wird das Projekt wichtige Impulse zur Task Area Data Connectivity, genauer für die vormodernen Nutzungsbeispiele (UC1) bei der Arbeit mit Normdaten (Measure 1) geben.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Durch die Dokumentation der Arbeitsprozesse, die Entwicklung von Typologien und die Bereitstellung der Daten nach FAIR-Prinzipien wird ein verbesserter Workflow geschaffen, der zukünftigen Projekten zugutekommen wird. Die Anbindung ans GWZO sowie die Beteiligung von erfahrenen Partnern wie der Polnischen Akademie der Wissenschaften in Krakow, der Friedrich-Schiller-Universitat Jena als FactGrid-Träger sowie der Deutschen Nationalbibliothek gewährleisten die wissenschaftliche Qualität und Nachhaltigkeit des Projekts. Die Modellierung von Daten bei FactGrid lebt aber von der Diskussion und der kollaborativen Anreicherung und Verbesserung der Daten. Insofern ist die Community zu jedem Zeitpunkt eingeladen, sich am Projektverlauf zu beteiligen. Diesen werden wir über den FactGrid-Blog dokumentieren, wodurch eine weitere, frei zugängliche Möglichkeit besteht, sich in den Diskussionszusammenhang unseres Projekts einzubringen. Darüber hinaus werden wir Projekt(zwischen)-ergebnisse an geeigneter Stelle auf Workshops oder Kongressen zur Diskussion stellen.
Weiterführende Links:
Datengeber Sven Jaros hat auf dem FactGrid-Blog bereits einen ersten
Problemaufriss zur Diskussion gestellt:
Sven Jaros, Modelling Premodern Political Entities - Case Studies from Eastern Europe, FactGrid.
A database for historians, 2024
Incubator Funds Projekte 2024
Projekttitel:
ASR4Memory. Ein KI-gestütztes Transkriptionsangebot für historische audiovisuelle Forschungsdaten
Projektlaufzeit:
Januar bis Dezember 2024
Projektverantwortliche & Beteiligte Einrichtungen:
Dr. Tobias Kilgus, Peter Kompiel, Freie Universität Berlin, Universitätsbibliothek
Das ist unser Ziel:
Das Projekt ASR4Memory entwickelt für die Forschungscommunity ein prototypisches Angebot
zur automatisierten Transkription von audiovisuellen Forschungsdaten in geschichtswissenschaftlichen Kontexten. Somit können historische audiovisuelle Ressourcen aus heterogenen Quellen in verschiedenen Sprachen für unterschiedliche Forschungs-, Nachnutzungs- und Archivierungsszenarien automatisiert transkribiert werden.
So wollen wir unser Ziel erreichen:
Das Vorhaben setzt - unter fachlich kritischer Auseinandersetzung mit dem Thema „Künstliche Intelligenz" - Open-Source-basierte Spracherkenner zur automatisierten Transkription (ASR) ein. Die audiovisuellen Forschungsressourcen werden in einem ersten Schritt automatisiert in höchstmöglicher Audioqualität aufbereitet, anschließend mit einer bestmöglichen Wortgenauigkeit spracherkannt und schließlich nach wissenschaftlichen Standards zeitkodierte Transkript- und Metadatenformate konvertiert. Geprüft wird zudem, ob durch ein Training und Finetuning der Spracherkennungsmodelle eine Verbesserung Transkriptionsergebnisse erzielt werden. Forschungsdaten werden datenschutzkonfom ausschließlich auf lokal betriebenen Servern der Universität verarbeitet.
Das hat unser Ziel mit 4Memory zu tun:
In der Forschungscommunity besteht ein großes Interesse, audiovisuelle Bestände technisch zu optimieren, nach wissenschaftlichen Standards in Textform bereitzustellen und inhaltlich zu erschließen sowie bei neuen Projekten die Nachnutzbarkeit mitzudenken. Dieses Angebot ermöglicht es, historische Forschungsressourcen - z.B. Zeitzeuge ninterviews, Dokumentarfilme oder Tonaufzeichnungen - automatisiert in der Originalsprache zu transkribieren und somit eine
wichtige Grundlage für die wissenschaftliche Erschließung der Ressourcen zu schaffen.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Der Mehrwert des Vorhabens liegt darin, sichere und fachlich kuratierte Infrastrukturen und anwendungsorientierte Workflows der Community bereitzustellen, welche automatisiertes und gleichzeitig hochqualitatives Transkribieren von mehrsprachigen Audio-Video-Datenbeständen ermöglicht. In einem Workshop, werden Mitglieder der Community ermutigt, ihre Bedarfe an das Projekt heranzutragen. Uber den Projektzeitraum hinaus soll ein tragfähiges Konzept für ein
nachhaltiges Betriebsmodell für die NFDI4Memory-Community entwickelt werden.
Weiterführende Links:
https://www.fu-berlin.de/asr4memory
Einen ausführlichen Projektbericht zum Nachlesen: Blogbeitrag ASR4Memory
Projekttitel:
Geodaten als Sozialdaten für die historische Längsschnittanalyse?
Ein experimentelles Projekt zum Einsatz von Drohnen
Projektlaufzeit:
4/24 - 11/24 (8 Monate)
Projektverantwortliche & Beteiligte Einrichtungen:
Prof. Dr. Kerstin Brückweh, Dr. Rita Gudermann, beide Leibniz-Institut für Raumbezogene
Sozialforschung (IRS) in Erkner
Werner-Reimers-Stiftung, Bad Homburg
Arbeitskreis „Sozialdaten und Zeitgeschichte"
Das ist unser Ziel:
Ergänzung von historischem Kartenmaterial aus dem IRS-Archiv durch aktuelle Drohnen-Luftbilder, Einsatz der Deep Mapping-Methode zur Herstellung von räumlichen Längsschnittdaten; Methodenpapier und Vorbereitung eines Fachaufsatzes (Peer-Review); Einbeziehung der historischen Akteure im Untersuchungsraum; Anregen der kritischen Diskussion über Geodaten als Sozialdaten; Entwicklung einer Strategie zur Archivierung von Geodaten.
So wollen wir unser Ziel erreichen:
Beschaffung von Karten und anderem Quellenmaterial in Archiven; Erfassung der Geodaten eines ausgewählten Untersuchungsgebiets mit Hilfe von Drohne und GNSS-Rover; Erarbeitung von digitalem Kartenmaterial mit Hilfe von QGIS (Deep Maps); Durchführung von Oral-History-Interviews und Einbindung von Citizen in das Projekt, Präsentation der Ergebnisse auf der Jahrestagung des Arbeitskreises 'Sozialdaten und Zeitgeschichte' in Bad Homburg; Verfassen der Projektpapiere
Das hat unser Ziel mit 4Memory zu tun:
Zusammenarbeit von Forschung, Memory Institutions und Infrastrukturen über projektbeteiligte Institutionen aktive Rolle von Archiv als Gedächtnisinstitution bei Auswertung und Generierung von Quellen (Geodaten als Sozialdaten); Integration von Deep Maps in bestehende Wissensordnung und Standards; Entwicklung von Standards für die Archivierung von Geodaten in Zusammenhang mit anderen Sozialdaten im Projekt
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Diskussion inhaltlicher und arbeitspraktischer Fragen auf der Jahrestagung des Arbeitskreises „Sozialdaten und Zeitgeschichte* in Bad Homburg durch Forschende und Vertreterinnen von Memory Institutions, Weitere Vernetzungstreffen und Workshops
Weiterführende Links:
https://leibniz-irs.de/forschung/forschungsschwerpunkte/zeitgeschichte-und-archiv
Projekttitel:
Hands-on Normdaten! Use Case zur communityorientierten, ressourceneffizienten und kreativen Implementierung der Gemeinsamen Normdatei (GND) in den Erschließungsworkflow einer staatlichen Archivverwaltung am Beispiel Bayerns
Projektlaufzeit:
1.2.2024 - 31.12.2024
Projektverantwortliche & Beteiligte Einrichtungen:
Leitung Dr. des Johannes Haslauer, Staatl. Archive Bayems/StA Bamberg.
Beteiligt: GND-Agentur BSB/BVB; IFLG Universitäten Bamberg und Bayreuth; Professur für Digitale Geschichtswissenschaften Universität Bamberg
Das ist unser Ziel:
Anhand eines Use Cases wollen wir Strategien und Methoden erarbeiten, um archivische Findmittel communityorientiert, ressourceneffizient und kreativ mit der Gemeinsamen Normdatei (GND) anzureichem und somit an die Anforderungen des semantic web anzupassen und gemäß den FAIR-Prinzipien besser nutzbar zu machen. Ziel ist die Implementierung in die Erschließungsworkflows, die Identifizierung von Weiterentwicklungsmöglichkeiten sowie die Partizipation der Community.
So wollen wir unser Ziel erreichen:
Zusammen mit den universitären Projektbeteiligten werden Beispiel-Datensets mit unterschiedlicher Zeitstellung und Strukturierung sowie mit Relevanz für die historisch arbeitenden Geisteswissenschaften zur Bearbeitung ausgewählt. Unter Anwendung des zur
Verfügung stehenden Toolsets werden die Daten angereichert und zur Verfügung gestellt. Daraus werden die strategisch-konzeptionellen Erkenntnisse, auch hinsichtlich der Aufwände
und der Skalierbarkeit, abgeleitet.
Das hat unser Ziel mit 4 Memory zu tun:
Wir wollen einen Beitrag dazu leisten, den Einsatz von Normierungsstandards wie der GND im Forschungsdatenmanagement von GLAM-Einrichtungen sowie von Forschenden voranzubringen (Datenkonnektivität). Datenqualität und Datenservices sind dabei von großer Bedeutung. Das Projekt soll auch helfen, Kompetenzen und Bewusstsein hinsichtlich des
Forschungsdatenmanagements auszubauen.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Die Ergebnisse sollen von GLAM-Einrichtungen nachnutzbar sein und Forschende zur Nutzung der GND anregen. Eine kollaborative Lehrveranstaltung und der Abschlussworkshop ermöglichen Partizipation.
Weiterführende Links:
www.gda.bayern.de
Projekttitel:
Maschinelles Sehen und Distant Reading auf Archivbestände für neue methodische Standards in der Provenienzforschung
Projektlaufzeit:
Februar bis Dezember 2024
Projektverantwortliche & Beteiligte Einrichtungen:
Jasmin Hartmann, Leiterin der Koordinationsstelle für Provenienzforschung in NRW (Gesamtprojektleitung) und Dr. Ruth von dem Bussche-Hünnefeld, Beraterin, Stellv. Ansprechpartnerin für den Arbeitskreis Provenienzforschung e.V. beim NFDI4Memory (Technische Projektleitung)
Das ist unser Ziel:
Ziel ist es, für die Provenienzforschung wesentlich maschinell erstellte Volltextdaten zu relevanten Archvidokumenten zu generieren und benutzerfreundlich als Suchmaschine zur Verfügung zu stellen. Damit werden große Aktenbestände in der fur die Provenienzforschung nötigen Tiefe erschlossen.
So wollen wir unser Ziel erreichen:
Wir setzen auf Verfahren der automatisierten Genenerung von Daten, d.h. über eine Dokumentenpipeline extrahierte Texte werden weiter maschinell verarbeitet (Entity Recognition/Extraction, Dokumentenerkennung). Wir evaluieren die angewandten Verfahren im Verarbeitungsprozess und bewerten diese qualitativ, um so Möglichkeiten und Grenzen der Anwendung aufzeigen zu können. Nutzer der Anwendung können mit Volltextsuchen und Facettierung arbeiten sowie Digitalisate über einen Bildserver nutzen. Volltexte und
Klassifikation der Dokumente stellen gegenüber archivischer Erschließung wesentliche neue
Metadaten dar.
Das hat unser Ziel mit 4 Memory zu tun:
Wir möchten die Verfahren maschineller Verarbeitungswege und die Erschließung von Archivbeständen verbessern helfen und die eingesetzten Verfahren im konkreten wissenschaftlichen Kontext evaluieren.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Die KPF.NRW wird im ersten Schritt die Methoden und Implikationen eines solchen Recherchetools gemeinsam mit dem Arbeitskreis Provenienzforschung e.V. (bereits Participant) bewerten. Wir freuen uns auf den Austausch mit weiteren Participants des Konsortiums insbesondere auch zum Output der eingesetzten technischen Verfahren. Die maschinelle Erschließung von Archivdokumenten kann dazu beitragen, die stetig wachsenden digital verfügbaren Aktenbeständen besser zu erschließen und in der Forschung nutzbar zu machen. Deshalb freuen wir uns auch auf den Austausch mit den Archiven.
Weiterführende Links:
Projekttitel:
NFDInspector – Datenqualität in Archiven und Museen. Entwicklung von Analyse-Tools als Python Package
Projektlaufzeit:
01.01.2024 - 31.12.2024
Projektverantwortliche & Beteiligte Einrichtungen:
Dr. Stefan Przigoda (Projektleitung), Andreas Ketelaer M. Sc. (Projektmitarbeit), Deutsches Bergbau-Museum Bochum, Montanhistorisches Dokumentationszentrum
Das ist unser Ziel:
Das Auffinden von Fehlern und die Messung von Qualität in den schnell wachsenden Datenbeständen der Gedächtnis- und Forschungseinrichtungen wird immer mehr zu einer quantitativen Herausforderung. Im Projekt werden praktische und frei nachnutzbare Werkzeuge für die systematische Sicherung der Datenqualität strukturierter Forschungsdaten von Museen und Archiven entwickelt. Damit sollen formale Qualitätsmängel in standardisiert vor liegenden Datensammlungen einfach identifiziert und Fehlerreports generiert werden können. Auf dieser Basis können weitere Maßnahmen zur Verbesserung der Datenqualitäten ergriffen werden.
So wollen wir unser Ziel erreichen:
Die projektierten Werkzeuge werden mittels der vor allem auch im Wissenschaftsbereich weit verbreiteten Programmiersprache Python programmiert. Zunächst liegt der Fokus auf LIDO und EAD als den gängigen Austauschformaten aus Museen und Archiven. Anschließend werden die Tools als Python Package im „Python Package Index" (PyPI) unter einer freien Lizenz veröffentlicht. Dies ermöglicht, dass Anwender:innen mit Basiskenntnissen in dieser Programmiersprache das Package leicht installieren und verwenden bzw. in ihre eigenen Anwendungen integrieren können. Perspektivisch können unter Verwendung des Packages so leichter zu bedienende oder auch mächtigere Tools zur Datenkuratierung entwickelt werden.
Das hat unser Ziel mit 4Memory zu tun:
Die Sicherstellung und Verbesserung der Qualität von Forschungsdaten aus den historischen Disziplinen ist ein Hauptziel von NFDI4Memory. Insbesondere in TA Data Quality sollen Messsysteme, Empfehlungen und Richtlinien zur Gewährleistung einer hohen Datenqualität erarbeitet werden. Im Rahmen des Vorhabens werden diese (in Teilen) unmittelbar in praktikable Applikationen übersetzt. Dies knüpft zudem an die Ziele von TA Data Connectivity an, in denen u.a. Konzeption, Planung und Entwicklung von Tools zur Datenkuratierung und Qualitätsmessung genannt werden.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Durch das Vorhaben werden Tools entwickelt und veröffentlicht, die in der Community unmittelbar zur Datenkuratierung verwendet werden können. Um die institutionenübergreifende Funktionalität der Tools sicherzustellen, sollen daher Testdaten verschiedener Einrichtungen in den Entwicklungsprozess miteinbezogen werden. Darüber hinaus sollen Möglichkeiten einer kollaborativen (Weiter-)Entwicklung von Tools erprobt werden. Entwickler:innen aus der Community können über den Projektrahmen hinaus zur Pflege, Verbesserung und Erweiterung des Packages beitragen.
Weiterführende Links: https://www.bergbaumuseum.de/forschung/forschungsprojekte/datenqualitaet-in-archiven-und-museen-entwicklung-von-analyse-tools-als-python-package
Projekttitel:
Paredros - Eine Grammatikentwicklungsgebung für Historiker. innen
Projektlaufzeit:
01.04.2024 - 31.12.2024
Projektverantwortliche & Beteiligte Einrichtungen:
Prof. Dr. Clemens Beckstein, Professor für Künstliche Intelligenz an der Universität Jena
apl. Prof. Dr. Robert Gramsch-Stehfest, Professur für Mittelalterliche Geschichte an der Universität Jena
Das ist unser Ziel:
Die Entwicklung einer Grammatikentwicklungsumgebung (GEU). Damit soll die Entwicklung von ANTLR-Grammatiken für Historikerinnen soweit vereinfacht werden, dass diese (weitgehend) ohne Hilfe von Informatikerinnen eine Codierung der syntaktischen Struktur der zu verarbeitenden Regesten (in Form der Grammatik) vornehmen können. Damit soll die Grundlage für eine automatisierte semantische Erschließung dieser Quellen gelegt werden.
So wollen wir unser Ziel erreichen:
... indem wir verschiedene Metriken für Text-Distanz-Messungen für vorstrukturierte Texte in der GEU implementieren, die wir für die Unterstützung des Grammatikentwicklungsprozesses nutzen werden. Dafür werden wir untersuchen, wie dieser Prozess durch ergonomische Komponenten zur Visualisierung und durch natürlichsprachliche Interaktionsmöglichkeiten für Nicht-Informatikerinnen erleichtert werden kann. Zu letzteren gehören einerseits das Vorschlagen von Standardkomponenten für die Komposition von ANTLR-Grammatiken und andererseits die Unterstützung bei der Identifikation von Entitäten wie Namen von Personen und Orten. Weiterhin soll erprobt werden, inwieweit LLMs automatisch natürlichsprachliche Zusammenfassungen der aus der Strukturanalyse resultierenden Sachverhalte generieren können.
Das hat unser Ziel mit 4 Memory zu tun:
Die vorgeschlagene GEU soll Forschende befähigen, ohne informatische Vorkenntnisse semantische Zusammenhänge aus semi-strukturierten Texten effizient zu extrahieren. Durch die kollaborative Anwendungsmöglichkeit der GEU wird eine Vernetzung der Forschenden gewährleistet und durch die Nachvollziehbarkeit der Auswertung die Quellenkritik direkt in die digitalen Tools integriert. Dadurch werden die Akzeptanz und Verbreitung von digitalen
Methoden in der Community nachhaltig gestärkt.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Mit Hilfe der vorgeschlagenen GEU können Historiker:innen, die mit umfangreichem digitalisiertem Material arbeiten, ohne Hilfe von Informatikerinnen, strukturierte Quellen (bspw. Regesten, Steuerlisten, Matrikellisten) effizient und erschöpfend auswerten, was bisher meist in einem zeitraubenden manuellen Prozess erfolgte. Um sicherzustellen, dass die Entwicklung der GEU ergonomisch zielführend ist, soll sie in enger Kooperation mit Historikerinnen anhand beispielhafter Auswertungen validiert werden. Hierbei freuen wir uns immer über Kooperationspartner.
Weiterführende Links:
https://doi.org/10.1515/9783110757101
Projekttitel:
Workshop-Reihe: Historische Arbeitstechniken. Aufbau Forschungsdatenbasis und Netzwerk zu Wissenstransfer
Projektlaufzeit:
Januar-Dezember 2024
Projektverantwortliche & Beteiligte Einrichtungen:
Dr. Lisa Maubach (LVR-Institut für Landeskunde u. Regionalgeschichte)
Ellen Bömler, Konrad Gutkowski (LWL-Museen für Industriekultur)
Das ist unser Ziel:
Wir möchten dabei unterstützen, dass das spezielle, handlungsbezogene Wissen zu historischen Arbeitstechniken und Produktionsprozessen mit digitalen Methoden gesichert und weitergegeben werden kann. Da es immer weniger Wissensträger innen in diesem Bereich gibt, wollen wir so dazu beitragen, dass z.B. museale Vorführbetriebe zukunftssicher aufgestellt sind und diese Form von immateriellem Kulturerbe erhalten bleibt.
So wollen wir unser Ziel erreichen:
Wir streben mit diesem Projekt die Gründung eines Interessennetzwerks an. Durch die Organisation verschiedener Workshop-Veranstaltungen (analog + digital) möchten wir gemeinsam die Grundlagen für die Arbeit im neuen Forschungsfeld "Erfahrung swissen zu historischen Arbeitstechniken" erarbeiten. Eine feste Ansprechperson wird den Prozess personell begleiten, um einen fundierten Aufbau und eine wissenschaftliche Begleitung des Netzwerks sicherzustellen.
Das hat unser Ziel mit 4 Memory zu tun:
Das Projekt unterstützt die Ziele der NFDI4Memory-Initiative durch Förderung einer aktiven Data Culture und Integration eines neuen Netzwerks. Es bindet verschiedene Akteursgruppen
ein, fördert Data Literacy und entwickelt Standards gemäß den FAIR-Prinzipien.
So kann die Community von unserem Vorhaben profitieren/sich einbringen:
Das Netzwerk zu historischen Arbeitstechniken bringt seine Expertise in die NFDI4Memory- Community ein. Akteur:innen aus verschiedenen Bereichen tragen Know-how bei und erweitern die Forschungsdaten. Ansätze zu bekannten sowie neuen analogen und digitalen Methoden zur Wissenssicherung und -weitergabe werden diskutiert. Die Tools und Methoden stehen für weitere Forschungsfragen offen zur Verfügung.
Weiterführende Links:
Pilot-Projekt vom LVR zum Thema: https://rheinische-
landeskunde.Ivr.de/de/alltagskultur/alltagskultur_projekte/wissenstransfer_projekt.html